Breakout thread from Discord: Discord
This chip was originally pointed out by members from UT.
I’ll try to copy+distill the DIscord thread into a better-formatted medium.
Background and initial impressions
Firstly, some meta-commentary on this device: it’s a chip design, not a board in itself. So if you ordered one of these nice $80 parts you’d have a silicon rectangle with pins on it, but not ports and I/O attached. It’s intended to be integrated into your own board. This is akin to the Jetson SoMs vs. the Jetson DevKits that are a reference design for a carrier board. The carrier board is generally not going to be optimized for size or durability, it’s optimized to let you use as much of the chip capabilities as possible. Unlike the Jetsons, this module doesn’t have DRAM built-in; you add that on the carrier board.
The official development board seems to be this one: SK-TDA4VM Evaluation board | TI.com.
Looking at what other boards exist, it looks like the BeagleBone AI-64 uses this chip:
- BeagleBone® AI-64 - BeagleBoard
- BeagleBone AI-64 SBC features TI TDA4VM Cortex-A72/R5F SoC with 8 TOPS AI accelerator - CNX Software
BeagleBoard is historically a great product line; I have a few Blacks sitting around, they’ve been a longstanding competitor to Raspberry Pi in a slightly more elegant form factor IMO. This board seems quite solid. And the good news about having a BeagleBoard using the chip is that they’ll have officially supported software, so that improves my original impression that well-understood software implementations would be sparse.
I’m not seeing other boards in my cursory search that use this chip in generic consumer products, but LMK if you find some; they may exist. Either way, I think the BeableBoard AI-64 would be an excellent choice if you/others go forward with using this chip on a robot. Honestly I’m dangerously close to impulse-purchasing one of these right now to add to my stack of microcontrollers and FPGAs.
The TDA4VM seems positioned in the market somewhere near a Jetson Nano. It’s a bit hard to compare 1:1 because the Jetson Nano is really focused on the GPU while the TDA4VM is a heterogeneous accelerator-oriented architecture, and a new one at that – it shares a lot less with a typical desktop PC/laptop/mobile phone than a Jetson does.
CPU specs
Regarding the easiest part to compare, the main CPU:
The TDA has a 2GHz dual-core Arm A72, while the Jetson Nano has a 1.5-ish quad-core Arm A57. The A72 is a few years newer and probably around 2x as performant as a ballpark – i.e., the TDA single-core performance will be significantly better than a Jetson Nano, I’d expect. It only has two cores in that complex vs. the Nano’s four, though, so multicore performance will be lower on the TDA than on the Jetson Nano. I’d still stack up the TDA’s main processor to be faster, but keep in mind you only have two parallel threads to work with. The TDA will be significantly less powerful than most of the other Jetsons, both since they have more cores and because many of them have Carmel/Denver cores which are supposedly pretty capable. But honestly single-core performance will probably be pretty similar to even a TX2 or Xavier NX.
Power
As a “thumb in the air” estimate for overall capability, I was trying to find ratings for power consumption of each chip. It looks like the Beagle is 15W or less, and the Nano is 10w or 15w, so they’re comparable in power consumption and that’s a good indication we’re doing the right analysis.
Vision compute power
Now we arrive at the hard part: the “vision processing” power, i.e. how capable the core is of running an ML model or classical vision algorithm. For a Jetson, this is a fairly simple and well-understood question. The Jetson Nano is a small but solid GPU, 128 CUDA cores. It runs pretty stock CUDA software and many libraries support it out-of-the-box. There are a good number of benchmarks online for common ML workloads. As a ballpark, it’ll run “typical” moderate vision models at around 30 FPS, e.g. ResNet-50 at 36 according to their numbers. Jetsons also have some vision accelerator chips and such on them, but you typically use them through DeepStream (used for the referenced benchmarks anyway) or not at all.
The TDA is harder. Aside from the main CPU, it has:
- A GPU. “PowerVR Rogue 8XE GE8430 3D GPU”, apparently. I have no idea how this performs or what software capabilities it has. It might not be useful for GPGPU compute.
- A deep learning accelerator and a vision processing accelerator, whatever those are. One of them is a programmable VLIW processor similar to a TPU, it seems. The other I can’t tell yet. But they both have some solid perf numbers that suggest they can do serious compute if you optimize your workload for them.
- A bunch (4x near the main CPU, plus 2 on their own lil I/O island I don’t understand) of Arm Cortex-R5F processors. These are full ARM microcontroller-class cores, similar to a typical Cortex-M{3,4} you’d find in e.g. an RM Dev Board. That’s quite slick. I’ll circle back to this later since I think it’s really interesting.
It’s difficult to do a proper numeric comparison on how much vision performance you can get out of the TDA, because:
- There are a bunch of different compute elements. Each of them has a different way you control it in software, different capabilities and limitations, different strengths and weaknesses, etc.
- You can’t simply “add up their performance” and get a number to compare with the Jetson GPU. Each of them does different kinds of things, so you’re e.g. probably only going to be using the “deep learning accelerator” (TPU) for ONNX machine learning inference. The dedicated GPU and “vision” accelerator probably aren’t very useful for running a machine learning model. (Note: an NVIDIA GPU supports lots of general-purpose computations, but many GPUs are just dedicated to graphics. The reference manual for the TDA claims some general-purpose abilities but I’m doubtful of software support.) So while the Jetson GPU is general-purpose, the various accelerators in the TDA processor each have their own place and aren’t interchangeable.
- A lot of the performance you get on this processor comes down to optimization. You need to figure out how to use the DL accelerator, or vision accelerator, or R5 coprocessors, and write your software to be aware of it. This is unlike Jetson code, which often works on any machine with an NVIDIA GPU.
- Some specific algorithms will benefit greatly from dedicated hardware. For example, there’s an accelerator chip which does stereo differencing and optical flow; if you’re computing distance from two camera images or estimating motion between frames of a video, those will help a lot. They’re useless otherwise.
I have not yet looked into the software tools they provide for interacting with the accelerators. The machine learning guides you guys linked above suggest that they have good tooling for running models on the DL accelerator, but I haven’t looked into how it works. However, here’s my take on the performance:
- Don’t under-estimate the work involved in supporting a heterogeneous compute platform. Figuring out all the various software APIs for each accelerator would take time and resources away from implementing the functionality you care about.
- Generic libraries like OpenCV are not going to be optimized for this device by default.
- Well-written software with this TDA chip in mind could absolutely perform the auto-aim task. The CPU is very capable (so long as your code is in C++, Rust, etc. and not Python) and the deep learning+vision accelerators can probably get you plenty good detection. But it’s hard to know for sure what this would take without trying it out.
Vision performance: Deep Learning
TI has published benchmarks of the TDA chip running standard deep learning models. These are naturally going to be a bit overly optimistic (they’ve been fine-tuned for this chip) but they’re a very solid foundation for comparison. And the results look great.
- Benchmark publication: https://www.ti.com/lit/pdf/spracz2
- Benchmark code: GitHub - TexasInstruments/edgeai-modelzoo: This repository has been moved. The new location is in https://github.com/TexasInstruments/edgeai-tensorlab

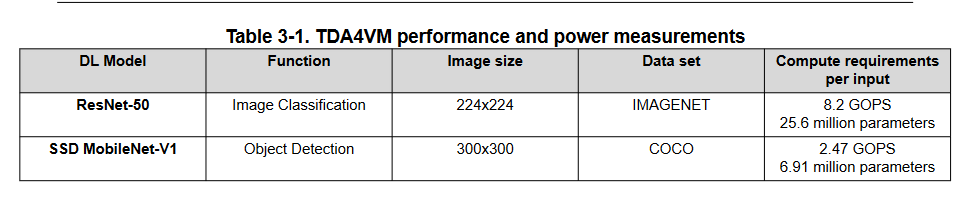

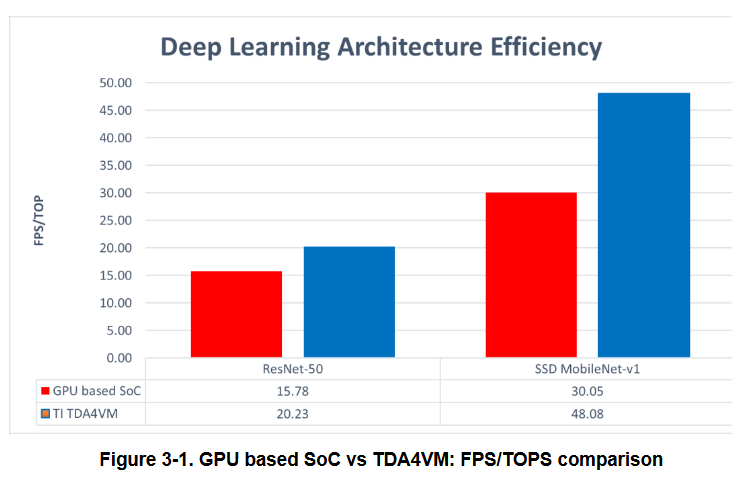
NVIDIA claims for the Jetson Nano: 36 FPS for a ResNet-50 at 224x224
TI claims for the TDA4VM: 162 FPS for a ResNet-50 at 224x224
So comparing 1:1 their official (i.e., absolute best case) benchmarks claims the TDA chip is a few times more performant than a Jetson Nano. Even if we assume NVIDIA was very realistic and TI over-reported dramatically, that still indicates the TI chip can punch above its weight class by a sizeable margin, in my estimation. I’d be curious to see if others can reproduce the results using the code they published.
It is important to note I haven’t looked at how much they quantized down the model or the resultant accuracy stats. It’s possible TI was e.g. running on INT8 and “cheating” a bit while NVIDIA left it at float32. I will need to look into it. But this gives me some great confidence that this board is a strong contender.
Realtime microcontroller cores (Cortex-R5)
Background
Traditionally, on an RM robot you need a microcontroller for running motors and I/O, plus a vision coprocessor for doing the heavy computation. This means you have two codebases, with wires and a point of failure in the middle. You’re limited by the data throughput and latency of the wires. You don’t have “immediate” access to sensor data when doing vision processing, or access to vision data when running controls and I/O loops. You need a dedicated “microcontroller” because a standard Linux OS will take milliseconds or more to do I/O (e.g. ask a motor to move, read a sensor) and might take tens of milliseconds to respond occasionally when the OS decides to context-switch. This is horrible for controlling motors, running PID, etc. Microcontrollers also boot “immediately” and are very resilient to power failure or physical impact. Meanwhile, Jetsons break or reset easily and take a minute or more to load.
This board
The TDA chip has a bunch of microcontrollers built in, which have access to I/Os (including CAN!) while sharing a memory space with the main processor. This seems to mean that you can write embedded microcontroller code for the Cortex-R5 processors that does I/O and computation of its own, and communicate “at the speed of memory” between them. That could be amazing for designing vision systems: you have a single processor with all motors, sensors, cameras, etc. plugged into it. You have embedded software processing the I/O, and Linux software processing the video. The Linux software is able to access live sensor measurements and broadcast full state back to the microcontroller. If you Linux software crashes, freezes, etc.: fine, it’ll restart. Meanwhile, all your motor and signaling is till being done, at full speed. And, perhaps best of all, you can centralize logging: have the Linux side aggregate logs of sensor data, actions, errors, etc. and save it on its end as the system goes. Plus maybe broadcast live data feeds via a network to be monitored as you debug.
These microcontrollers are Cortex-R5 processors. There are four of them which are directly tied to the main CPU complex – Linux software loads and controls the firmware they run, and shares a bunch of I/O resources – and then two separate from the CPU complex which I don’t fully understand.
The “R” variant is for “realtime”, which means they have different interrupt handling mechanisms (although, I can’t tell why they are different in the way they are). The important bit is they’re clocked at 1GHz and are around 30% more performant per MHz than an M4 core, so you’d get around 5-10x more performance from each of these cores than the M4 you have in your RM Dev Board. So the TDA chip has 6 over-powered dev boards built in! These do seem to have access to external I/O. You could presumably port normal controls code over to them using standard CAN peripherals, with really easy interop to communicate with the vision software.
Some discussion: Minimal Cortex-R5 example on BBAI-64 - General Discussion - BeagleBoard
Ecosystem
The ecosystem will be naturally split according to which board you use. Some content will be applicable to all TDA4VM-based boards, other content will be specific to peripherals or provided software on one.
The main two board options I see are the BeagleBoard AI-64 and the official TI evaluation board. BB has forums with some moderately lively discussion: Topics tagged bbai64. TI has forums as well with slightly more quantity and less quality, it seems.
One of the big limiting factors you’ll run into with diverging from the Jetson line is that you have even less library support. E.g., there’s definitely no official software for the ZED or RealSense cameras on this chip. They have a “robotics SDK” project with a home-grown ZED driver, which is interesting. But this stuff won’t come easy.
Conclusion: technical analysis
The TDA4VM looks like a great chip for embedded vision. It has plenty of compute power for a vision system and will be similar in form factor to a Jetson Nano. The software support is a big unknown, you’ll be paving the way as you go since very few others have used the device. I think the BeagleBoard AI-64 seems like the best option right now given the limited general-purpose carrier boards I see, but please do post if you see other options.










